Actor-Critic
Actions space: Discrete|Continuous
References: Asynchronous Methods for Deep Reinforcement Learning
Network Structure
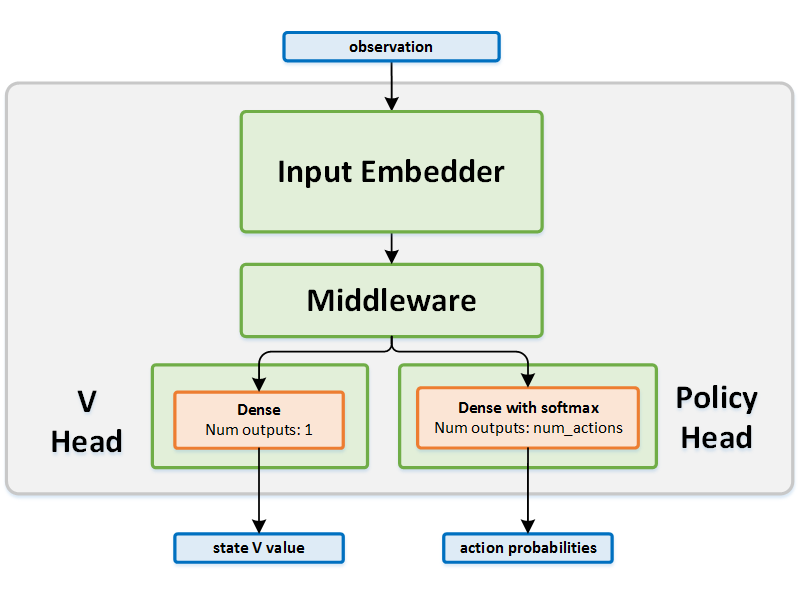
Algorithm Description
Choosing an action - Discrete actions
The policy network is used in order to predict action probabilites. While training, a sample is taken from a categorical distribution assigned with these probabilities. When testing, the action with the highest probability is used.
Training the network
A batch of transitions is used, and the advantages are calculated upon it.
Advantages can be calculated by either of the following methods (configured by the selected preset) -
- A_VALUE - Estimating advantage directly:where is for each state in the batch.
- GAE - By following the Generalized Advantage Estimation paper.
The advantages are then used in order to accumulate gradients according to