N-Step Q Learning
Actions space: Discrete
References: Asynchronous Methods for Deep Reinforcement Learning
Network Structure
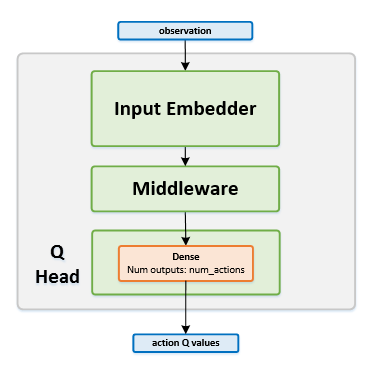
Algorithm Description
Training the network
The -step Q learning algorithm works in similar manner to DQN except for the following changes:
-
No replay buffer is used. Instead of sampling random batches of transitions, the network is trained every steps using the latest steps played by the agent.
-
In order to stabilize the learning, multiple workers work together to update the network. This creates the same effect as uncorrelating the samples used for training.
-
Instead of using single-step Q targets for the network, the rewards from consequent steps are accumulated to form the -step Q targets, according to the following equation: where is for each state in the batch